BIANA (Biologic Interactions and Network Analysis) is a biological database integration and network management framework written in Python. It uses a high level abstraction schema to define databases providing any kind of biological information (both individual entries and their relationships).
EnrichNet is a network-based enrichment analysis method to identify functional associations between user-defined gene or protein sets and cellular pathways. The datasets are mapped onto a protein interaction network (or other user-defined molecular network) and their pairwise associations are assessed by computing a graph-based statistic, i.e. distances between the network nodes are mapped against a background model. In contrast to the classical overlap-based enrichment analysis, associations can also be identified for non-overlapping gene/protein sets and the user can investigate them in detail by visualizing corresponding sub-graphs.
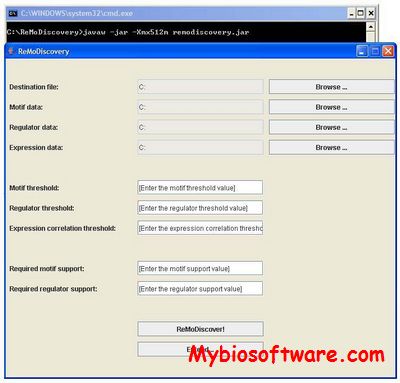
ReMoDiscovery is an intuitive algorithm to correlate regulatory programs with regulators and corresponding motifs to a set of co-expressed genes. It exploits in a concurrent way three independent data sources: ChIP-chip data, motif information and gene expression profiles.
CytoHiC is a plugin for the Cytoscape platform which allows users to view and visually compare spatial maps of genomic landmarks, based on normalized Hi-C data.
CFNet combines a novel rotation equivariant convolution scheme, called conic convolution, and the DFT to aid networks in learning rotation-invariant tasks. This network has been especially designed to improve performance of CNNs on automated computational tasks related to microscopy image analysis.
WebPropagate is a web-server that implements variants of network propagation on up-to-date PPI networks. Starting from a seed set of proteins that are known to be associated with a process of interest, WebPropagate outputs additional candidate proteins that are significantly associated with the seed set.
PhosNetConstruct is a tool to predict novel phosphorylation networks based on the preference of certain kinase families to phosphorylate specific functional protein families (domains). It identifies the potentially phosphorylated proteins from a given set of proteins and predicts target kinases which in turn would phosphorylate these identified phosphoproteins based on their domain compositions.
PRINCE (PRIoritizatioN and Complex Elucidation) is a method for prioritizing disease associated genes.PRINCIPLE (PRINCe ImPLEmentation) is a client-server implementation of PRINCE