Bio C# contains classes for handling fasta IO, Blast-search (using an own algorithm), local and global alignments, quality sequence IO, statistics (Mann-Whitney, Poisson Distribution), distribution of features along chromosomes, SNP-identification, gene expression statistics, 454-sequence handling, microsatellite search and basic sequence statistics
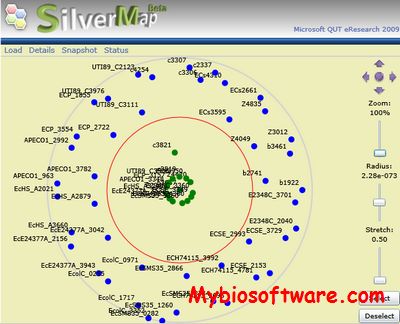
QUT.Bio focuses on tools for bioinformatics and computational biology; new approaches to visualize sequences and the relationships between them—through SilverMap and SilverGene; and methods for promoter prediction, pattern description languages, and mash-ups.
CDK (The Chemistry Development Kit) is a Java library for structural chemo- and bioinformatics.The CDK provides methods for many common tasks in molecular informatics, including 2D and 3D rendering of chemical structures, I/O routines, SMILES parsing and generation, ring searches, isomorphism checking, structure diagram generation, etc.
pygr is a bioinformatics toolkit for sequence analysis and comparative genomics. pygr is highly scalable (e.g. one can easily query multi-genome alignments) and easy to use
Pygr is open source software to develop graph database interfaces for the popular Python language to make it easy to do powerful sequence and comparative genomics analyses, even with extremely large multi-genome data sets. pygr includes:
Code for interacting with sequence databases, search methods such as BLAST, repeat-masking, megablast, etc.;
Querying and working with sequence annotation databases and sequence alignment datasets;
A data namespace for accessing a given resource with seamless data relationship management.
Easy data sharing that includes transparent access over network protocols.
High performance graph representation and query of interval-based data.
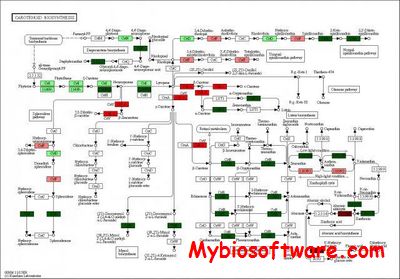
PAICE (Pathway Analysis and Integrated Coloring of Experiments) is a rapid bioinformatics pathway visualization tool for KEGG-compatible accessions derived from Illumina Solexa next-gen and Affymetrix datasets. It colors KEGG pathways while appreciating detection-calls and duplicate gene copies.
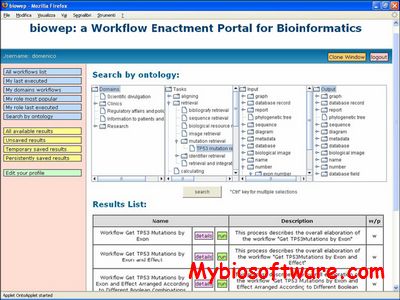
biowep is a web based client application that allows for the selection and execution of a set of predefined workflows. The system is available on-line. Biowep architecture includes a Workflow Manager, a User Interface and a Workflow Executor.
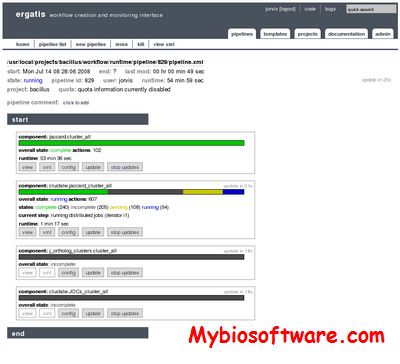
Ergatis is a web-based utility that is used to create, run, and monitor reusable computational analysis pipelines. It contains pre-built components for common bioinformatics analysis tasks. These components can be arranged graphically to form highly-configurable pipelines. Each analysis component supports multiple output formats, including the Bioinformatic Sequence Markup Language (BSML). The current implementation includes support for data loading into project databases following the CHADO schema, a highly normalized, community-supported schema for storage of biological annotation data.
BioDB-Loader toolkit loads several bioinformatics databases into Lisp for facile processin. BioDB-Loader contains utilities for loading flatfiles from the Swiss-Prot, Prosite, Enzyme, EcoCyc, and MetaCyc databases.