BioMyn is a comprehensive online resource that integrates information related to human genes and proteins from over a dozen external databases. It includes Gene Ontology annotations of human genes and proteins, sequence family classifications, protein domain architectures, metabolic and signaling pathways, protein interactions and protein complexes, and disease associations.
CalSpec (Calculate Spectra) is a software module for fast processing of mass spectrometric data in 13C Metabolic Flux Analysis(MFA). Efficient MFA requires a straightforward approach that can be parallelized and automated for all steps involved. A time-consuming and error prone step in the whole procedure of MFA is the extraction of labeling patterns from mass spectrometric spectra. CalSpec for identification of amino acids TBDMS derivates, addresses this problem and provides a software module for automated identification of specified analytes in the MS spectrum, quantification of labeling patterns and estimation of the analyte peak quality.
The C3Part/Isofun package implements a generic approach to the local alignement of two or more graphs representing biological data, such as genomes, metabolic pathways or protein-protein interactions, in order to infer functional coupling between them.
[1] Syntons, Metabolons and Interactons: an exact graph-theoretical approach for exploring neighbourhood between genomic and functional data. F. Boyer, A. Morgat, L. Labarre, J. Pothier and A. Viari Bioinformatics 21:4209-4215 (2005)
[2] Multiple alignment of biological networks: A flexible approach. Y.-P. Deniélou, F. Boyer, M.-F. Sagot, and A. Viari. In CPM’09, volume 5542 of Lecture Notes in Computer Science, pages 173-185. Springer-Verlag, 2009.
[3] Bacterial syntenies an exact approach with quorum. Y.-P. Deniélou, F. Boyer, M.-F. Sagot, and A. Viari. BMC Bioinformatics – submitted 2011
BioRAT (Biological Research Assistant for Text mining) is a search engine and information extraction tool for biological research.A large and growing amount of information is published every year in scientific journals. In the biomedical field, there are thousands of journals, each publishing many issues annually, any one of which could contain information that is relevant to a researcher. However, no one has time to read every paper. One solution is to use a software tool to search through publications to identify important results in response to the users’ queries. BioRAT is such a tool.
ViewCommonPaths program helps to simultaneously visualize a set of numeric sequences that have the same start and end elements by drawing them into a common directed acyclic graph (DAG). In particular, ViewCommonPaths helps to simultaneously visualize a set of allosteric communication paths with the same start and end residues. Given a set of allosteric paths (each a sequence of residues), ViewCommonPaths creates a DAG from the set of individual pathways and allows a quick visual analysis of these pathways and the relationships among the residues along these paths.
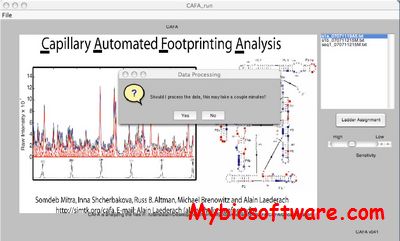
CAFA is Capillary Automated Footprinting Analysis algorithms. The use of capillary electrophoresis with fluorescently labeled nucleic acids revolutionized DNA sequencing, effectively fueling the genomic revolution. We present an application of this technology for the high-throughput structural analysis of nucleic acids by chemical and enzymatic mapping (‘footprinting’). We achieve the throughput and data quality necessary for genomic-scale structural analysis by combining fluorophore labeling of nucleic acids with novel quantitation algorithms.The accuracy, throughput and reproducibility of CAFA analysis are demonstrated using hydroxyl radical footprinting of RNA. The versatility of CAFA is illustrated by dimethyl sulfate mapping of RNA secondary structure and DNase I mapping of a protein binding to a specific sequence of DNA. Our experimental and computational approach facilitates the acquisition of high-throughput chemical probing data for solution structural analysis of nucleic acids.