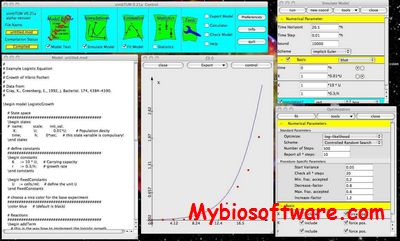
simbTUM allows to define ODE-models or stochastic compartemental models of biological processes, to simulate, to fit data and to do some statistics (fitting and statistics for deterministic models only).
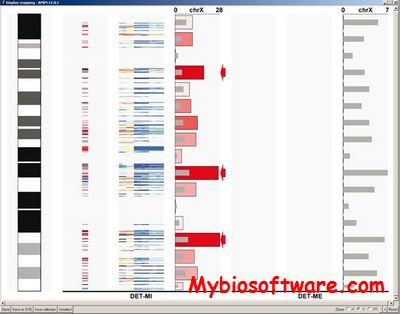
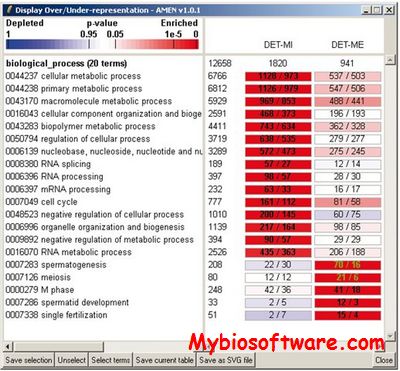
AMEN (Annotation, Mapping, Expression and Network) is a stand-alone, unified suite of tools to manage, explore and combine biological multifaceted high-throughput data such as annotation, chromosomal location, expression and interaction data.
MyMiner is a free and user-friendly text annotation tool aimed to assist in carrying out the main biocuration tasks and to provide labelled data for the development of text mining systems.
BRISK is a package of several web-based data management tools that provide a cohesive data integration and management platform. It was specifically designed to provide the architecture necessary to promote collaboration and expedite data sharing between scientists.
Bioperl is a collection of Perl modules that facilitate the development of Perl scripts for bioinformatics applications. As such, it does not include ready to use programs in the sense that many commercial packages and free web-based interfaces do (e.g. Entrez, SRS). On the other hand, Bioperl does provide reusable Perl modules that facilitate writing Perl scripts for sequence manipulation, accessing of databases using a range of data formats and execution and parsing of the results of various molecular biology programs including Blast, clustalw, TCoffee, genscan, ESTscan and HMMER. Consequently, bioperl enables developing scripts that can analyze large quantities of sequence data in ways that are typically difficult or impossible with web based systems.
Biochemistry Lab Suite app aims in helping scientists and students working in the field of mass spectrometry based proteomics, metabolomics, biochemistry, biology and chemistry but also aids in general lab work.
BioECS is an ad hoc search engine to help biologists to isolate EST clusters corresponding to their research target, based on cross references between TIGR and Unigene. It allows to filter out EST clusters by combining several criteria based on information about tissues, species, and development stages associated to the EST sequences that form the clusters. The user interface allows to easily access all EST sequences forming the clusters and to browse known GO (Gene Ontology) functions associated to them. The client/server software architecture is based on JAVA and MySQL. It comprises a ‘server’ program responsible for the web-based transactions and local caching of information from the public database servers. A ‘client’ program allows biologists to execute researches.
::DEVELOPER
the Systems and Modeling research unit at the University of Liège (Belgium).
Judi ( Java platform for unsupervised data and model integration ) is a software written in Java, with an aim to provide a user-friendly tool for general unsupervised data and model integration. For many problems in biology, such as gene function prediction and differentially expressed gene identification, and general feature selection problems, there are often multiple data sources available and/or multiple models/tools have been developed to solve the problem. The combination of evidences from multiple data sources and the integration of the output from different models will probably enhance our ability to solve the problem. Judi implements several algorithms and also provides a user-friendly interface to facilitate this process.
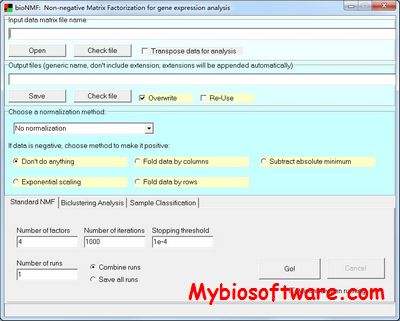
bioNMF is a web-based tool designed to provide a set of analysis methods using the Non-negative Matrix Factorization (NMF) model, widely used in the last few years by the biomedical community due to its intuitive nature, since it has the ability to extract highly-interpretable additive parts from datasets, reducing therefore its dimensionality.
BioStat is a user-friendly biology and medicine oriented statistical software.With BioStat 2009, one gets a robust suite of statistics tools and graphical analysis methods that are easily accessed though a simple and straightforward interface.